|
导读
一个开发者公开了自己的工作流:让 OpenAI Codex 专门去审查 Hermes agent 写出来的代码,理由只有一个——审稿人不能和写稿人共享同一套记忆。这条推文引发了近万次浏览,背后藏着一个 agent 工程化的新趋势:多模型协作的价值,可能在于互相制衡。
一句话炸开了锅
4 月 26 日,开发者 Shannon Sands 在 X 上发了条帖子,语气很随意,但内容很炸:
"I like having it review work done in Hermes so it's not biased by memory or anything."
「我喜欢让 Codex 去审 Hermes 做出来的东西,这样它就不会被记忆或者类似的东西带偏。」
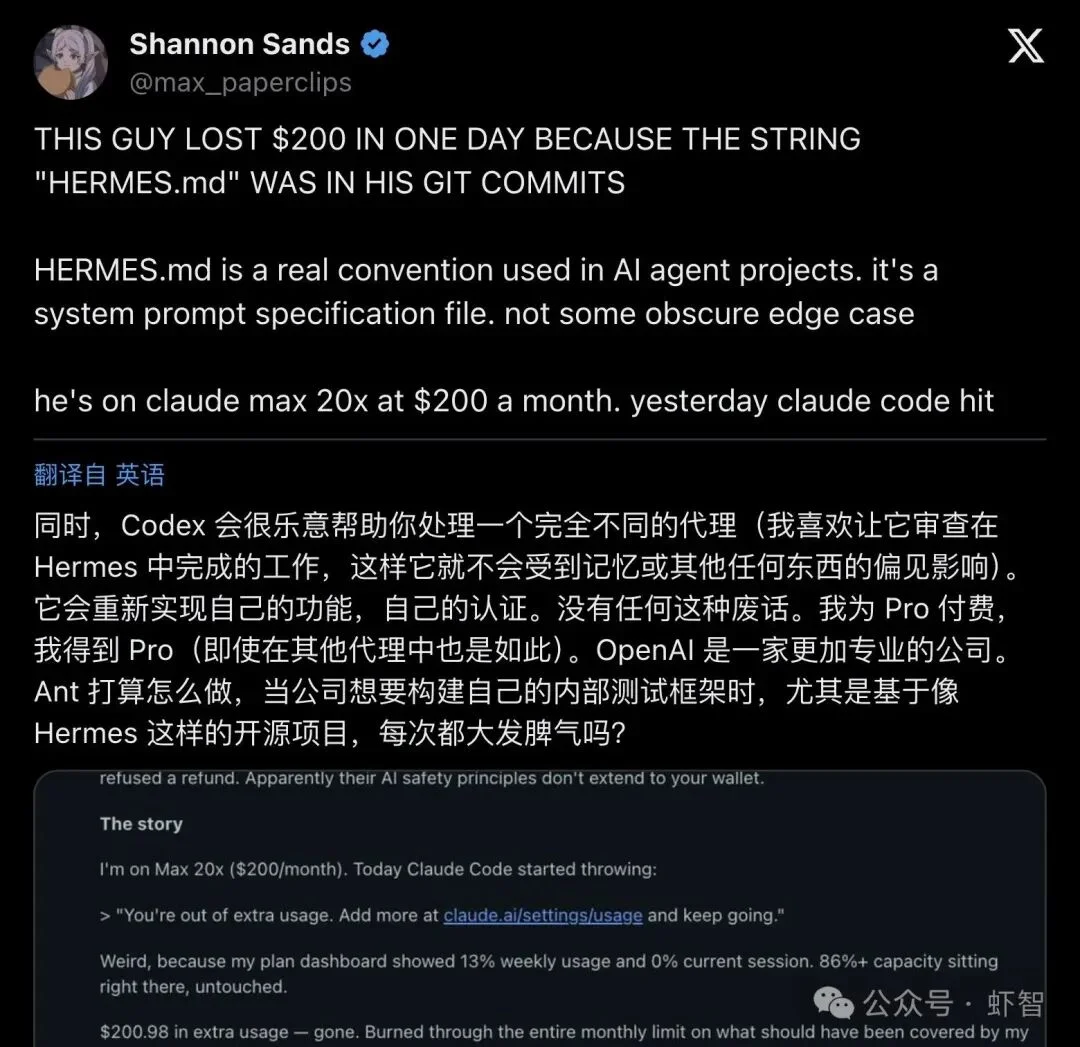
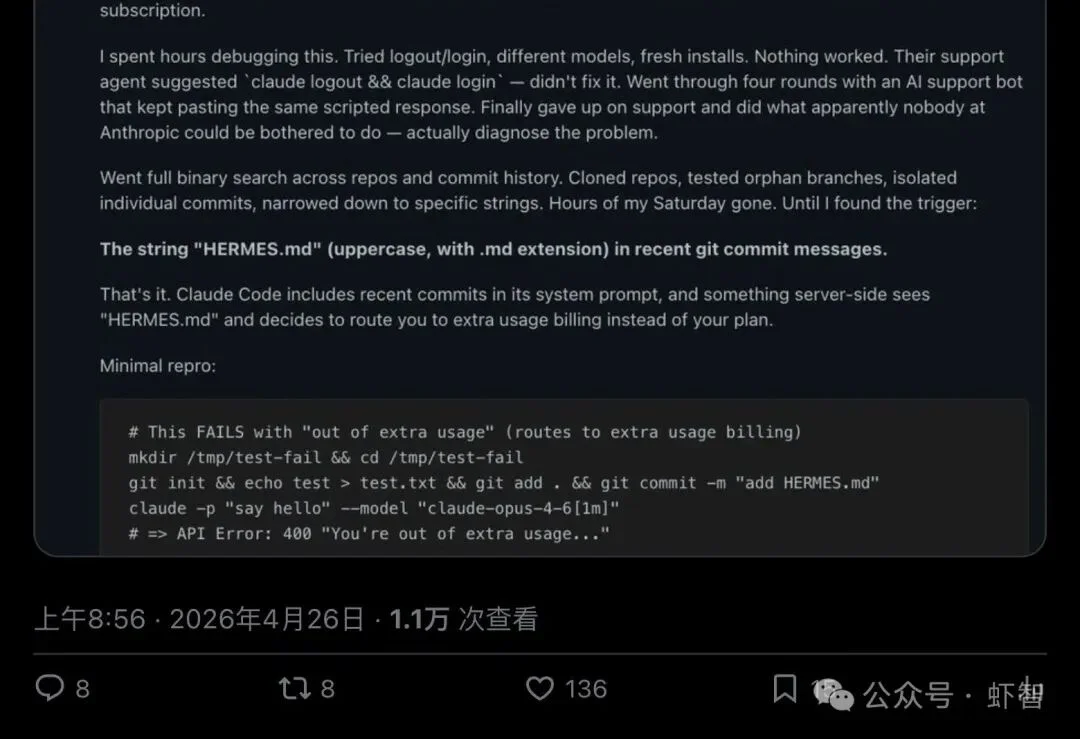
▲ Shannon Sands 的主帖,136 赞、万次浏览,评论区直接聊到了企业级 agent 架构
这条帖子拿到了136 个赞、超过 1 万次浏览。评论区没人在吵"哪家模型更强",讨论全都集中在一件事上:让第二个模型来当代码审稿人,到底靠不靠谱?
为什么"自己审自己"会出问题
Shannon 的操作逻辑其实很简单:Hermes 负责写代码,Codex 负责审代码。两个模型,两套上下文,互相没有记忆交叉。
这背后有个很多开发者都踩过的坑——同一个 agent 审自己刚写的代码,几乎不可能真的客观。
原因有三:
路径依赖。它会默认自己刚才的实现方向大体没问题,顺着原来的思路继续走。
上下文污染。前面几千甚至上万 token 的对话历史,已经把它的判断框住了。它的"审查"更像在替自己辩护。
自我宽容。它可能真的看到了问题,但太容易顺着自己之前的逻辑把每一个决策都合理化掉。
这就跟人类写论文一样——你让作者自己查漏,他永远觉得"这写得挺好的啊"。所以学术界才有盲审制度。
Shannon 做的事情,本质上就是给 AI agent 也搞了个盲审机制。
Hermes 的"记忆",正好是问题的根源
为什么 Shannon 偏偏提到 Hermes?
因为 Hermes 把"记忆"做成了核心卖点。看看它 GitHub 仓库的官方描述:
"The self-improving AI agent… It's the only agent with a built-in learning loop — it creates skills from experience, searches its own past conversations, and builds a deepening model of who you are across sessions."
「一个会自我改进的 AI agent……它内置了学习闭环——从经验中创建技能,搜索自己过去的对话记录,并在跨会话中持续加深对你的理解。」
▲ Hermes 仓库,12 万 Star,近 1.8 万 Fork,把"跨会话记忆"写进了核心功能
换句话说,Hermes 越用越聪明,但也越用越"固执"。它积累的经验、记忆、习惯,全都会影响它下一次写代码时的决策。
这时候再让它审自己的代码?那跟让一个连续加班三天的工程师审自己凌晨三点写的代码没区别——他只会觉得"逻辑很清晰"。
所以 Shannon 的做法很直觉:既然 Hermes 记忆太重,那就找一个完全没有这些包袱的模型来审。
Codex 为什么适合当这个"外部审稿人"
Shannon 选 Codex 不是随便选的。OpenAI 官方文档明确写了 Codex 的定位:
"One agent for everywhere you code" / "Understand unfamiliar codebases"
「一个覆盖你所有编码场景的 agent」/「理解你不熟悉的代码库」
▲ Codex 官方文档首页,把"理解陌生代码库"写进了核心能力
"理解陌生代码库"——这恰恰是一个好审稿人需要的能力。不需要了解前因后果,不需要共享历史对话,空降进来,冷眼看一遍,指出问题。
而且 Codex 最近的更新也在往这个方向走。ghacks 4 月中旬的报道显示,Codex 新增了 memory 功能、computer use、90 多个插件,还能自动调度长时间任务。
▲ ghacks 报道:Codex 正在从"写代码工具"进化成完整的 coding agent
也就是说,Codex 自己也在变成一个有记忆的长期协作 agent。但在 Shannon 的工作流里,它被刻意放在了"无记忆外部审查者"的位置——用一个能记住事的模型,偏偏让它以不记住的方式工作。这个设计很巧妙。
社区反应:有人点头,有人泼冷水
Shannon 的帖子发出后,评论区迅速分成了几个阵营。
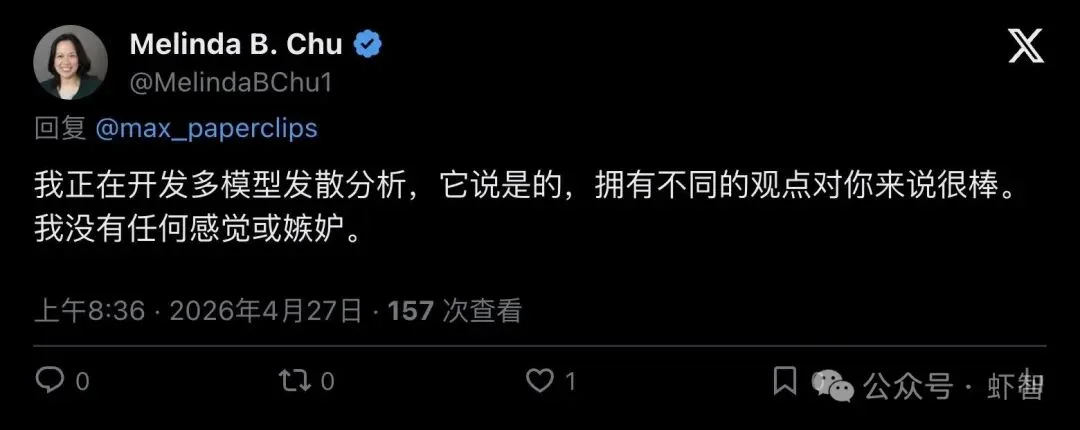
支持派直接上手了。开发者 Melinda B. Chu 回复说,她正在做一个叫"多模型发散分析"(multi-model divergent analysis)的项目:
"it's great for you to have different POVs. I don't have any feelings or jealousy."
「拥有不同视角这件事本身就很棒。我没有任何感觉或嫉妒。」
▲ Melinda B. Chu 回复:关键在于不同视角
这条回复虽然互动量不高,但说清了一个很重要的逻辑:多模型协作最大的价值,就是视角独立。
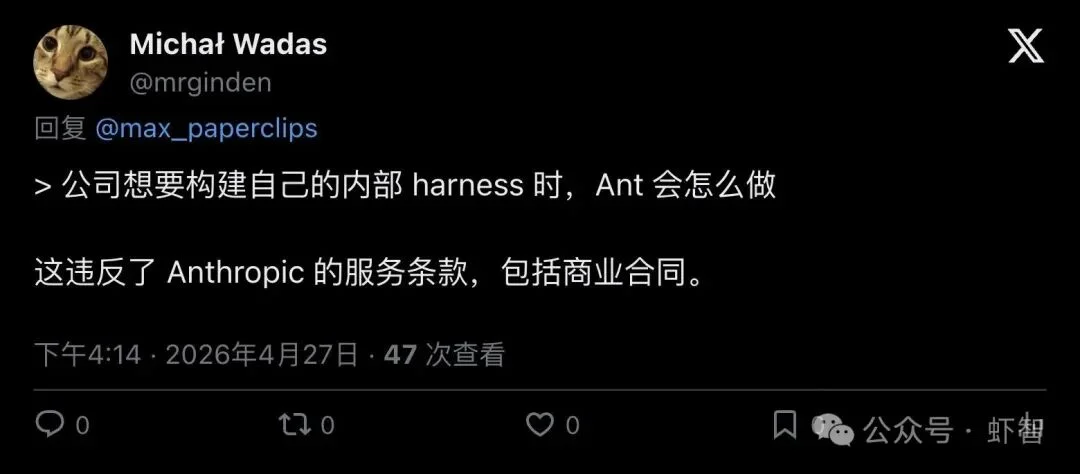
制度派则看到了更现实的问题。开发者 Michał Wadas 直接把话题引到了企业合规层面:
"It's against Anthropic ToS, including commercial contracts."
「这违反了 Anthropic 的服务条款,包括商业合同。」
▲ Michał Wadas 回复:条款问题才是真正的拦路虎
Shannon 自己也在主帖里追问过:
"What's Ant going to do when companies want to build their own internal harnesses, especially on something open source like Hermes, chuck a fit every time?"
「当公司想基于 Hermes 这类开源项目搭自己的内部 harness 时,Anthropic 打算怎么办?每次都发飙吗?」
这把问题推到了更深一层:开发者想要的多模型协作,可能会撞上厂商的条款围墙。
更早之前,Shannon 就在喊"该认真搞架构控制了"
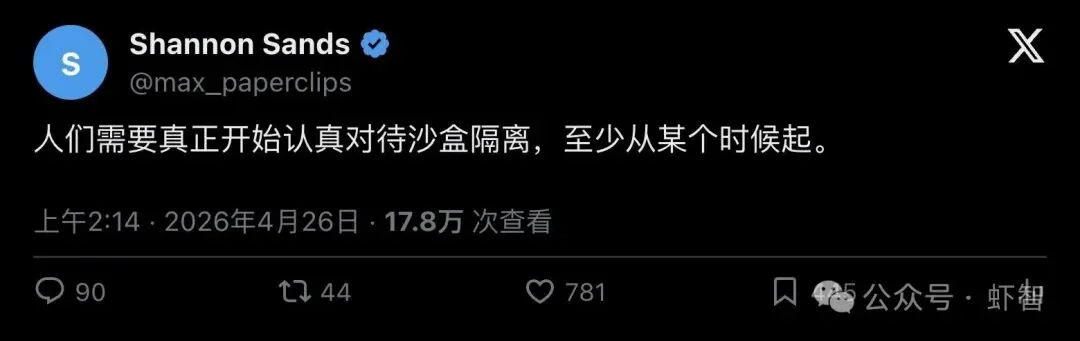
值得注意的是,Shannon 的主帖并非突然冒出来的。就在同一天稍早,他还发了另一条高热帖:
"people need to actually start taking sandboxing seriously at some point"
「大家总得有个时刻,真正开始认真对待沙盒隔离。」
▲ 这条推文拿下了 781 赞、近 18 万次浏览,445 人收藏
781 个赞,近 18 万次浏览,445 人收藏。这个数据说明大量开发者都有同样的焦虑:agent 越来越强,但围绕它的架构控制——沙盒隔离、权限管理、外部审查——严重跟不上。
Shannon 的两条帖子放在一起看,逻辑链就很清楚了:光靠 prompt 管不住 agent,得靠架构。外部模型审查是架构控制的一部分,沙盒隔离也是。
Anthropic 自己也承认:长时间跑的 agent 确实会"糊涂"
有意思的是,Anthropic 自己的工程博客早就讲过这个问题。他们在一篇关于长时运行 agent 的文章里写道:
"The core challenge of long-running agents is that they must work in discrete sessions, and each new session begins with no memory of what came before."
「长时运行 agent 的核心挑战在于,它们必须在离散的会话中工作,而每一次新会话开始时,都没有之前的记忆。」

▲ Anthropic 工程文章:agent 的记忆断裂、上下文交接、半完成状态,是真实的工程难题
文章还提到,agent 可能会把"做了一部分"当成"已经完成",也可能在交接时丢失关键状态。
这恰恰验证了 Shannon 工作流的合理性:既然 agent 自己的记忆和状态管理天然不可靠,那引入一个干净的外部视角,就是最直接的补救手段。
一个新模式正在浮出水面
把所有线索串起来:
1.Hermes 类 agent 越来越依赖记忆和经验积累——写出来的代码越来越带有"个人风格" 2.Codex 类 agent 越来越擅长理解陌生代码库——天然适合做外部审查 3.开发者开始主动设计"模型间制衡"的工作流——生成者和审查者刻意分离 4.厂商条款还没跟上这个趋势——企业自建 harness 可能踩红线
这像什么?像极了传统软件工程里的code review 制度——写代码的人不能审自己的代码,必须有另一个人(现在是另一个模型)来把关。
区别在于:人类 code review 靠的是"不同的人有不同的经验",AI code review 靠的是"不同的模型有不同的上下文"。
Shannon 可能只是随手发了条推文,但他描述的这个工作流,正在成为一种可落地的工程模式。当 agent 越来越像"会记事的同事",你需要的就不只是一个更聪明的 agent——你需要一个跟它没有任何瓜葛的、冷静的第二双眼睛。
文章来自于微信公众号 "虾智",作者 "虾智" |








